|
SEO��Search Engine Optimization�����h�g���������惞(y��u)������һ�N��ʽ���������������Ҏ(gu��)�t��߾W(w��ng)վ�����P(gu��n)���������(n��i)����Ȼ������Ŀ���ǣ���W(w��ng)վ�ṩ���B(t��i)ʽ�����ҠI�N��Q�����������ИI(y��)��(n��i)ռ��(j��)�I(l��ng)�ȵ�λ���@��Ʒ�����棻SEO����վ��SEO��վ��(n��i)SEO�ɷ��棻���ˏ����������Ы@�ø�������M�������ľW(w��ng)վ�Y(ji��)��(g��u)����(n��i)�ݽ��O(sh��)�������Ñ����ӂ��������ȽǶ��M�к���Ҏ(gu��)����߀��ʹ�����������@ʾ�ľW(w��ng)վ���P(gu��n)��Ϣ���Ñ���f�������������� �������������̎�팦���ǻ�(li��n)�W(w��ng)�W(w��ng)퓣���ǰ�W(w��ng)퓔�(sh��)���ك|Ӌ���������������������R�Ć��}���ǣ�����܉��O(sh��)Ӌ����Ч�����dϵ�y(t��ng)���Ԍ���˺����ľW(w��ng)퓔�(sh��)��(j��)���͵����أ��ڱ����γɻ�(li��n)�W(w��ng)�W(w��ng)퓵��R���ݡ� �����W(w��ng)�j(lu��)���x��������ã�������������ϵ�y(t��ng)�к��P(gu��n)�IҲ�����A(ch��)�Ę�(g��u)�����@����Ҫ��B�c�W(w��ng)�j(lu��)���x���P(gu��n)�ļ��g(sh��)���M�����x���g(sh��)��(j��ng)�^��ʮ��İl(f��)չ�������w��������������죬���S��(li��n)�W(w��ng)�IJ���l(f��)չ��Ҳ���R��һЩ������(zh��n)�Ե����}�� �����D��ʾ��һ��ͨ�õ����x������̡����ȏĻ�(li��n)�W(w��ng)����о����x��һ���־W(w��ng)퓣����@Щ�W(w��ng)퓵�朽ӵ�ַ����N��URL�����@Щ�N��URL�����ץȡURL����У����x�Ĵ�ץȡURL��������xȡ������URLͨ�^DNS��������朽ӵ�ַ�D(zhu��n)�Q��W(w��ng)վ����(w��)������(y��ng)��IP��ַ�� ����Ȼ����;W(w��ng)�����·�����Q���o�W(w��ng)����d�����W(w��ng)����d��ؓ(f��)؟(z��)����(n��i)�ݵ����d���������d�����صľW(w��ng)퓣�һ���挢��惦�������У��ȴ����������Ⱥ��m(x��)̎��;��һ���挢���d�W(w��ng)퓵�URL������ץȡURL����У��@�����ӛ�d�����xϵ�y(t��ng)�ѽ�(j��ng)���d�^�ľW(w��ng)�URL���Ա���W(w��ng)퓵��؏�(f��)ץȡ�����ڄ����d�ľW(w��ng)퓣����г�ȡ��������������朽���Ϣ��������ץȡURL����Йz�飬����l(f��)�F(xi��n)朽�߀�]�б�ץȡ�^���t���@��URL�����ץȡURL���ĩβ����֮���ץȡ�{(di��o)���Е����d�@��URL����(y��ng)�ľW(w��ng)퓡�����@�㣬�γ�ѭ�h(hu��n)��ֱ����ץȡURL��О錏���@���������xϵ�y(t��ng)�ь��܉�ץȡ�ľW(w��ng)퓱M��(sh��)ץ�꣬�˕r�����һ݆������ץȡ�^�̡� 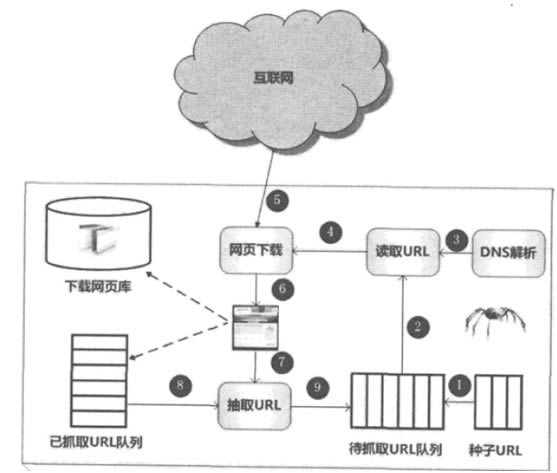 �����������x���f������߀��Ҫ�M�оW(w��ng)�ȥ�ؼ��W(w��ng)퓷����ס� ����������һ��ͨ�����x�����w���̣�����ĸ��Ӻ��^�ĽǶȿ��]��̎�ڄӑB(t��i)ץȡ�^���е����x�ͻ�(li��n)�W(w��ng)���оW(w��ng)�֮�g���P(gu��n)ϵ�����Դ�������D2-2�����ǘӣ�����(li��n)�W(w��ng)��愝�֞�5�����֣� ����1.�����d�W(w��ng)퓼��ϣ����x�ѽ�(j��ng)�Ļ�(li��n)�W(w��ng)���d�������M�������ľW(w��ng)퓼��ϡ� ����2.���^�ھW(w��ng)퓼��ϣ����ھW(w��ng)퓔�(sh��)������x����ץȡһ݆��Ҫ�^�L�r�g����ץȡ�^���У��ܶ��ѽ�(j��ng)���d�ľW(w��ng)퓿����^�ڡ�֮������ˣ�����黥(li��n)�W(w��ng)�W(w��ng)�̎�ڲ���ĄӑB(t��i)׃���^���У������a(ch��n)�����ؾW(w��ng)퓃�(n��i)�ݺ��挍��(li��n)�W(w��ng)�W(w��ng)퓲�һ�µ���r�� ����3.�����d�W(w��ng)퓼��ϣ���̎���ψD�д�ץȡURL����еľW(w��ng)퓣��@Щ�W(w��ng)퓼��������x���d�� ����4.��֪�W(w��ng)퓼��ϣ��@Щ�W(w��ng)�߀�]�б����x���d��Ҳ�]�г��F(xi��n)�ڴ�ץȡURL����У����^ͨ�^�ѽ�(j��ng)ץȡ�ľW(w��ng)퓻����ڴ�ץȡURL����еľW(w��ng)퓣������܉�ͨ�^朽��P(gu��n)ϵ�l(f��)�F(xi��n)����������r��������xץȡ�������� ����5.����֪�W(w��ng)퓼��ϣ���Щ�W(w��ng)퓌������x���f�ǟo��ץȡ���ģ��@���־W(w��ng)퓘�(g��u)���˲���֪�W(w��ng)퓼��ϡ����ϣ��@���־W(w��ng)���ռ�ı����ܸߡ� ��������(j��)��ͬ�đ�(y��ng)�ã����xϵ�y(t��ng)���S�����ڲ�����w���ԣ����Ԍ����x���֞��������N���: ����1. ���������x(Batch Crawler)�����������x�б��^���_��ץȡ������Ŀ��(bi��o)����(d��ng)���x�_(d��)���@���O(sh��)����Ŀ��(bi��o)��ֹͣץȡ�^�̡����ھ��wĿ��(bi��o)���ܸ�����Ҳ�S���O(sh��)��ץȡһ����(sh��)���ľW(w��ng)퓼��ɣ�Ҳ�S���O(sh��)��ץȡ���ĵĕr�g�ȡ� ����2.���������x(Incremental Crawler)�����������x�c���������x��ͬ�������ֳ��m(x��)�����ץȡ������ץȡ���ľW(w��ng)퓣�Ҫ���ڸ��£���黥(li��n)�W(w��ng)�ľW(w��ng)�̎�ڲ���׃���У������W(w��ng)퓡��W(w��ng)퓱��h�����߾W(w��ng)퓃�(n��i)�ݸ��Ķ��ܳ�Ҋ�������������x��Ҫ���r��ӳ�@�N׃��������̎�ڳ��m(x��)�����ץȡ�^���У�������ץȡ�¾W(w��ng)퓣������ڸ������оW(w��ng)퓡�ͨ�õ��̘I(y��)�����������x�������ٴ�� ����3.��ֱ�����x(Focused Crawter)����ֱ�����x�P(gu��n)ע�ض����}��(n��i)�ݻ��ߌ����ض��ИI(y��)�ľW(w��ng)퓣����猦�ڽ����W(w��ng)վ���f��ֻ��Ҫ�Ļ�(li��n)�W(w��ng)퓶����ҵ��c�������P(gu��n)������(n��i)�ݼ��ɣ������ИI(y��)�ă�(n��i)�ݲ��ڿ��]��������ֱ�����xһ���������c���y�c���ǣ�����R�e�W(w��ng)퓃�(n��i)���Ƿ����ָ���ИI(y��)�������}���Ĺ�(ji��)ʡϵ�y(t��ng)�YԴ�ĽǶȁ��f����̫���ܰ����л�(li��n)�W(w��ng)������d��֮����ȥ�Y�x���@�����M�YԴ��̫�^���ˣ�������Ҫ���x��ץȡ�A�ξ��܉�ӑB(t��i)�R�eij���W(w��ng)ַ�Ƿ��c���}���P(gu��n)�����M����ȥץ�՟o�P(gu��n)��棬���_(d��)����(ji��)ʡ�YԴ��Ŀ�ġ���ֱ�����W(w��ng)վ���ߴ�ֱ�ИI(y��)�W(w��ng)վ������Ҫ�˷N��͵����x�� ��������(n��i)���Ɂ������W(w��ng)��վ�L�����D(zhu��n)�dՈע����̎���x�x! �������惞(y��u)���ڇ���l(f��)չѸ�٣�����(n��i)Ҳ�б���ă�(y��u)���ۺ��ߡ�ͨ�^�˽�����������ץȡ��(li��n)�W(w��ng)��桢�M�������Լ��_���䌦�ض��P(gu��n)�I�~�����Y(ji��)�������ȼ��g(sh��)���팦�W(w��ng)��M�����P(gu��n)�ă�(y��u)����ʹ�������������������
|
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l(f��)����Win7������ϵ�y(t��ng)��Win10�������XP������ϵ�y(t��ng)�H�邀�ˌW(xu��)��(x��)�yԇʹ�ã�Ո�����d��24С�r��(n��i)�h�������������κ��̘I(y��)��;����t�����ؓ(f��)��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW(w��ng)�j(lu��)�YԴ,���ַ������ę�(qu��n)��,Ո���r֪ͨ�҂�($email$),�҂������r̎��.
Copyright © 2018-2020 win10ϵ�y(t��ng)���dվ
